AI Weekly #008
🆕 更新了什么?
产品更新:
- 发布了 ComflowySpace v0.0.8-alpha,Load image 节点支持 Mask editor 功能,以及下拉菜单增加图片预览功能,选择图片更方便。
- 模型 Tab 增加了模型推荐功能。各位可以从这里看到我们认为值得下载的模型。
- 下载链接:Comflowyspace (opens in a new tab)
新增教程:
🤩 每周 AI 精选
📄 值得关注的论文 & 技术
字节发布的 SDXL-Lightning 基于 Progressive Distillation 和 Adversarial Distillation 提升蒸馏效果,只需几步即可生成高质量的 1024px 图像。在定量和定性对比上,效果要优于 Turbo 和 LCM。同时类似 LCM-LoRA,SDXL-Lightning 还提供了蒸馏的 LoRA 版本,可以兼容其它 SDXL 基底模型。感兴趣可以试试。
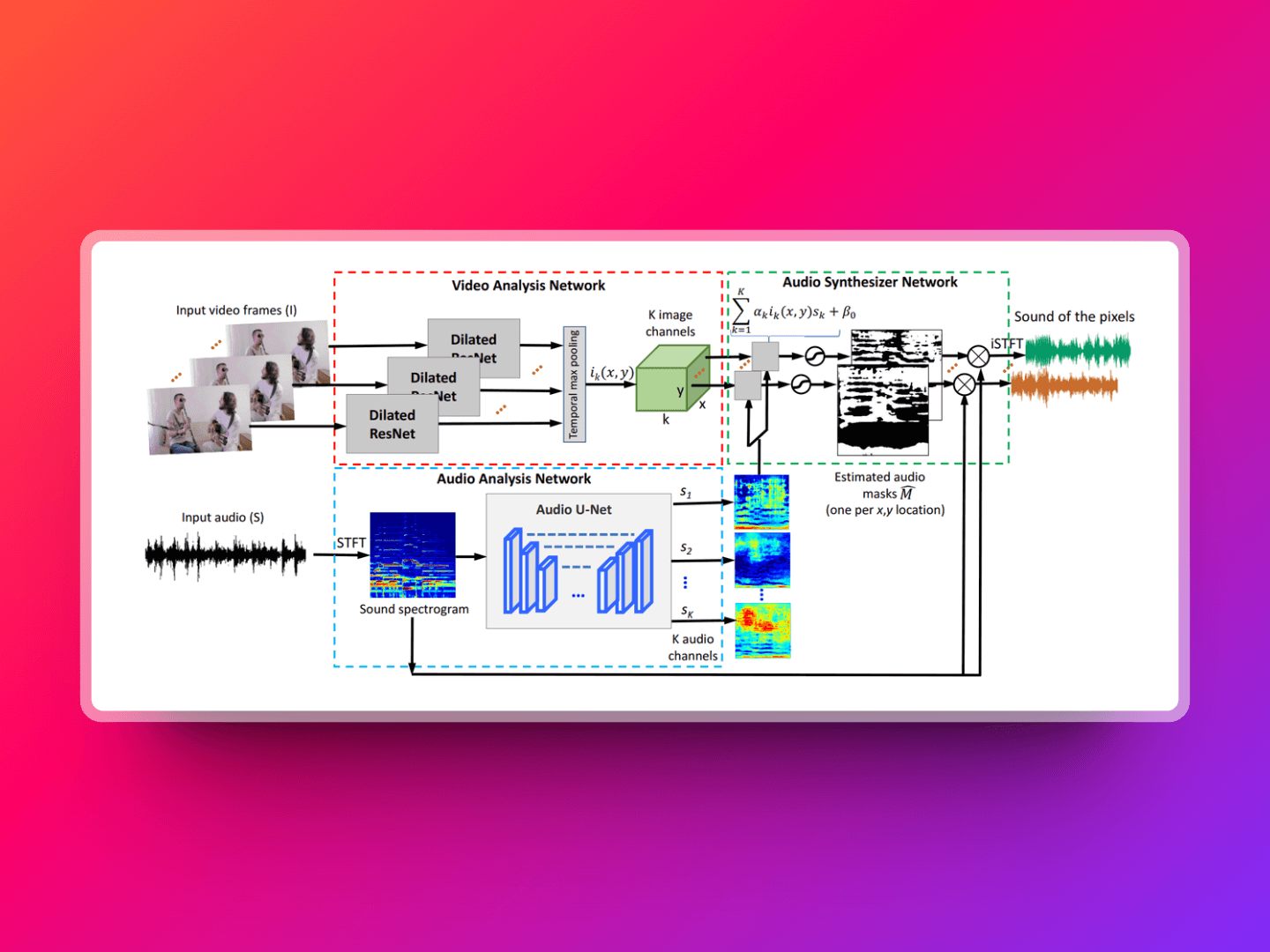
这是 MIT 研究团队开发的项目,能自动从视频中识别和分离出不同的声音源,并与画面位置匹配。例如,它可以识别出视频中哪个人物正在说话,或哪个乐器正在被演奏。而且还能够分别提取和分离这些声音源的声音。PixelPlayer 能自我学习分析,无需人工标注数据。 这种能力为音视频编辑、多媒体内容制作、增强现实应用等领域提供了强大的工具,使得例如独立调整视频中不同声音源音量、去除或增强特定声音源等操作成为可能。
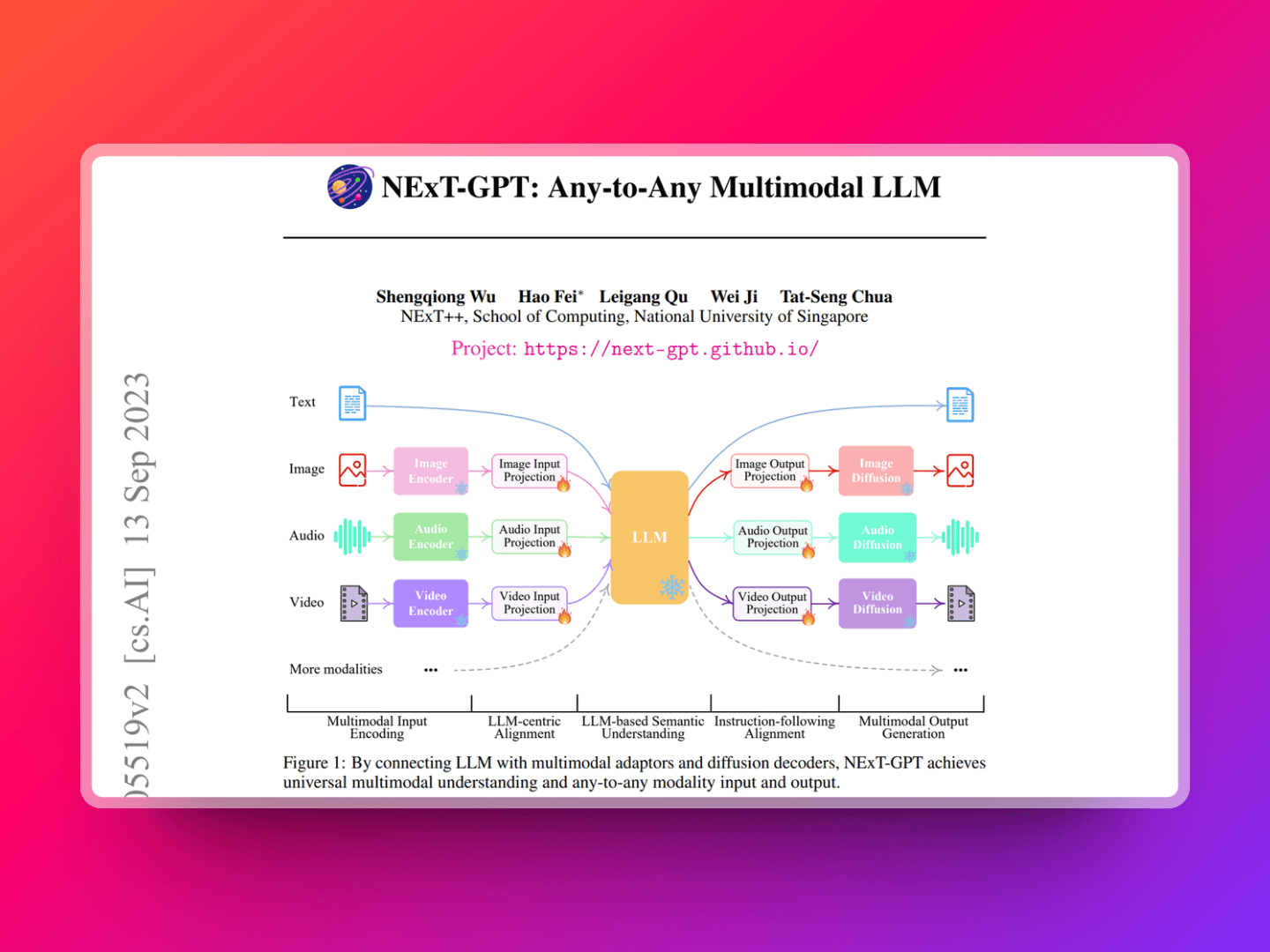
AnyGPT 是一种创新的多模态语言模型,它通过离散化处理,将图像、语音、音乐等多种模态的数据统一为语言模型可以理解的标记序列。这种处理方式使得 AnyGPT 能够在不同的模态之间进行无缝转换,从而在理解和生成内容时更加灵活和高效。例如,它可以将一段描述性文本转换为相应的图像,或者根据一段音乐生成相应的歌词,这种能力在以往的语言模型中是难以实现的。
YOLOv8 能够在图像或视频帧中快速准确地识别和定位多个对象,还能跟踪它们的移动,并将其分类。除了检测对象,YOLOv8 还可以区分对象的确切轮廓,进行实例分割、估计人体的姿态、帮助识别和分析医学影像中的特定模式等多种计算机视觉任务。

🛠️ 值得尝试的产品
OpenAI 推出的视频生成大模型 Sora,具备生成包含多个角色、具体的运动方式,以及精确主题和背景细节的复杂场景的能力。这个模型不只是理解用户在提示中的需求,还能理解这些需求在物理世界如何实现。 Sora 使用了扩散模型来将复杂、抽象的片段细化,直到形成清晰的图像。此外,他还利用了 Transformer 架构来处理连续的视频帧,使得视频中的动作(例如花的盛开,阳光的移动)看起来流畅自然。

谷歌发布了两种权重规模的开源 LLM 模型:Gemma 2B(20 亿参数)和 Gemma 7B(70 亿参数)。它与谷歌规模最大、能力最强的 AI 模型 Gemini 共享技术和基础架构。每种规模都提供了预训练和指令微调版本,使用条款允许所有组织(无论规模大小)负责任地进行商用和分发。
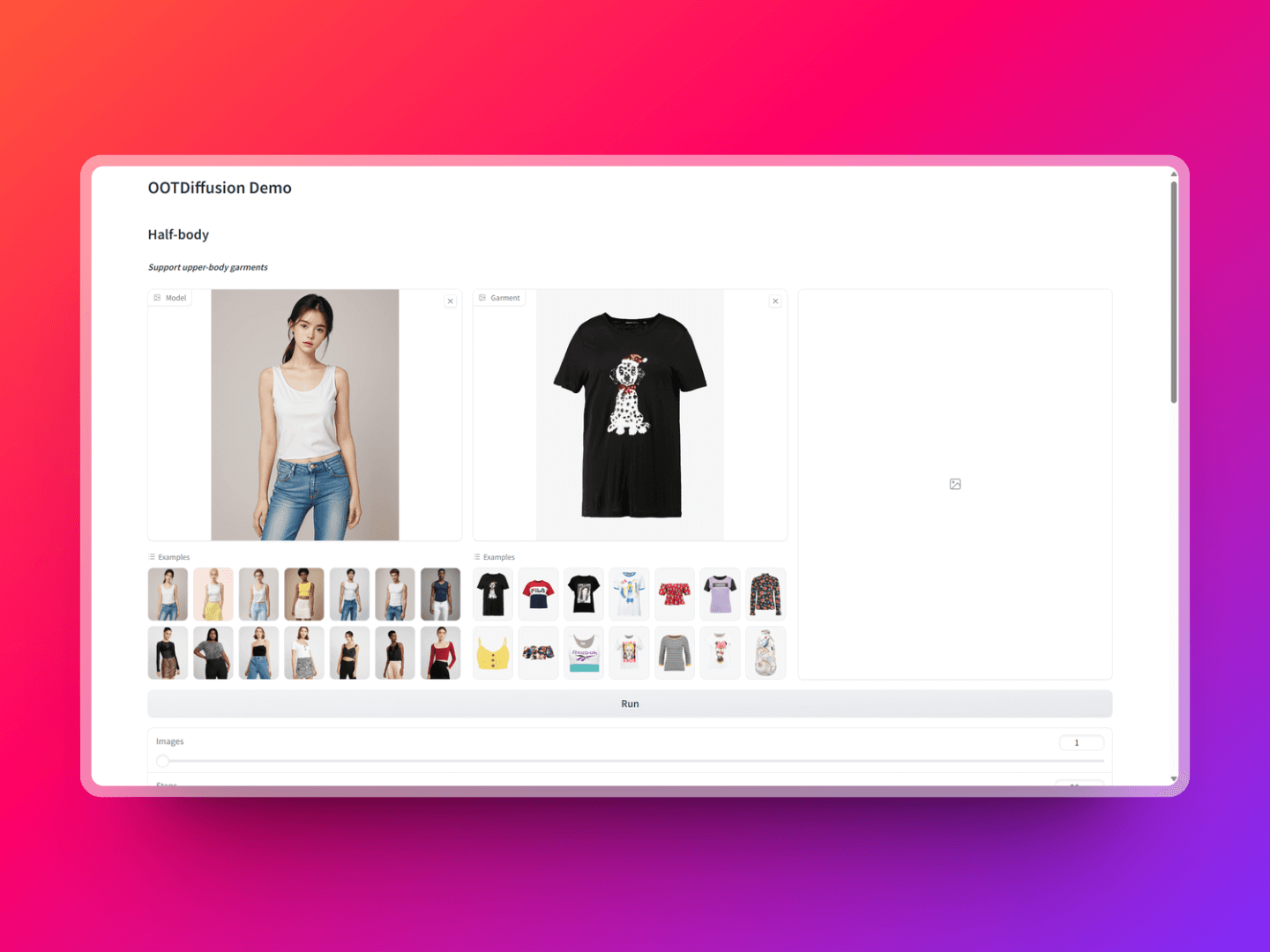
OOTDiffusion 是一种基于潜在扩散的虚拟试穿技术,其主要目的是通过实现控制性的换装融合,让用户能够在虚拟环境中试穿不同的服装。该技术通过融合最新的机器学习算法与图像处理技术,为用户提供了一种新颖的虚拟试穿体验。这个开源工具,支持半身模型和全身模型两种模式。还可以根据自己的需求和偏好调整试穿效果,服装效果图和模特非常贴合。感兴趣可以试试。