文生图
上一章,我们介绍了 Stable Diffusion 的基本原理,以及如何使用它生成图片。这一章,我们来介绍 ComfyUI 和 Comflowy 的基本操作,以及如何使用 AI 生成图片。
学习本章前,请确保你已经完成 ComfyUI 的安装,并且下载好了 Stable Diffusion v1.5 或 Stable Diffusion XL 模型。并将模型文件放到对应的文件夹内。
如果你想要使用本章的工作流,可以使用下载使用 Comflowy 本地版,或者注册使用 Comflowy 云端版本 (opens in a new tab),里面都内置了本章的工作流。并且如果你使用的是云端版本,你可以直接使用我们内置的模型,无需下载。
默认 Workflow
如果你使用的是 Comflowy,打开应用后,你会看到这样的一个界面,如果你使用的是我们的云端版本,应该也是类似的界面。
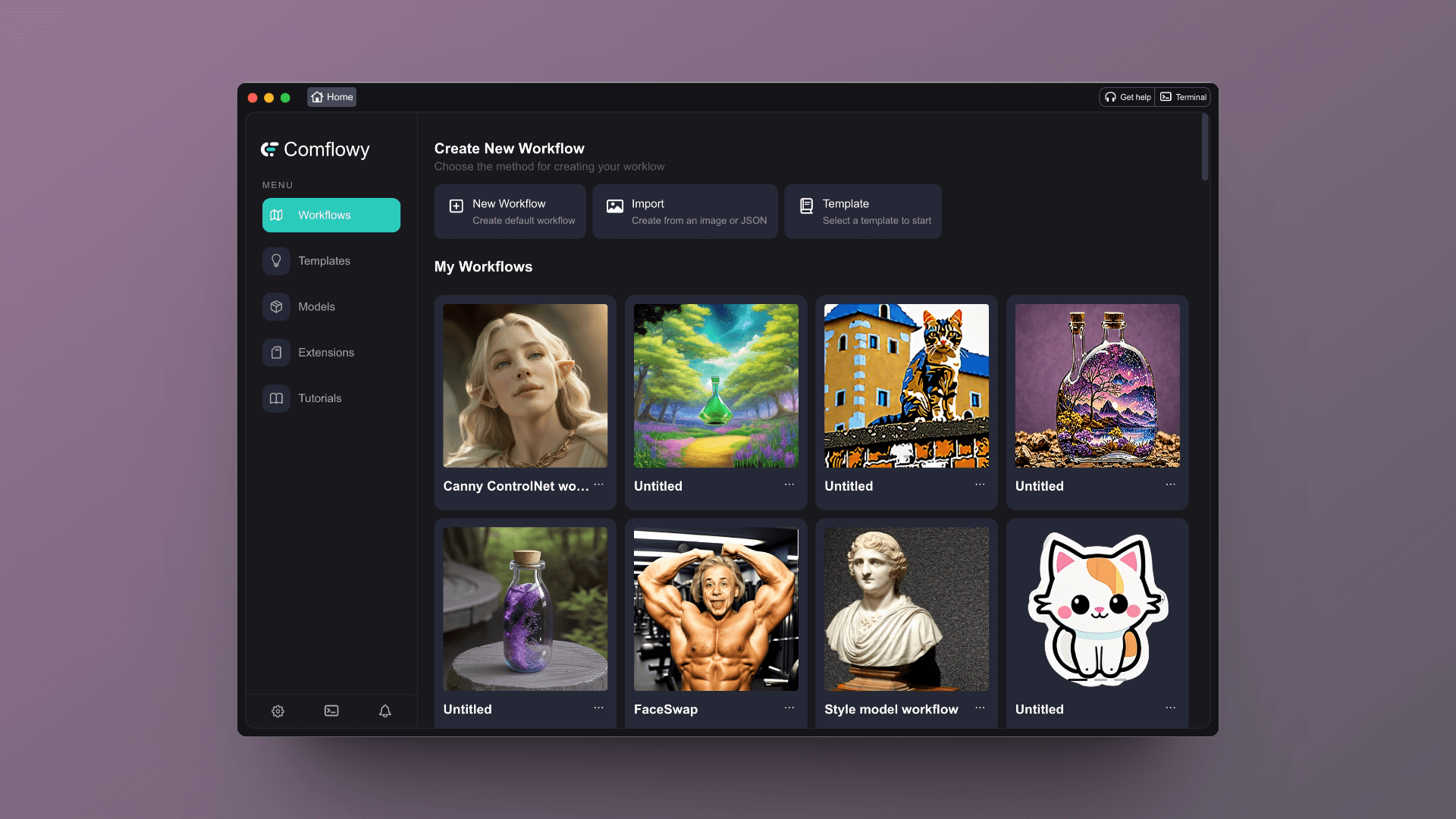
点击顶部的 New workflow(新建工作流)按钮,你会看到这样的一个界面:
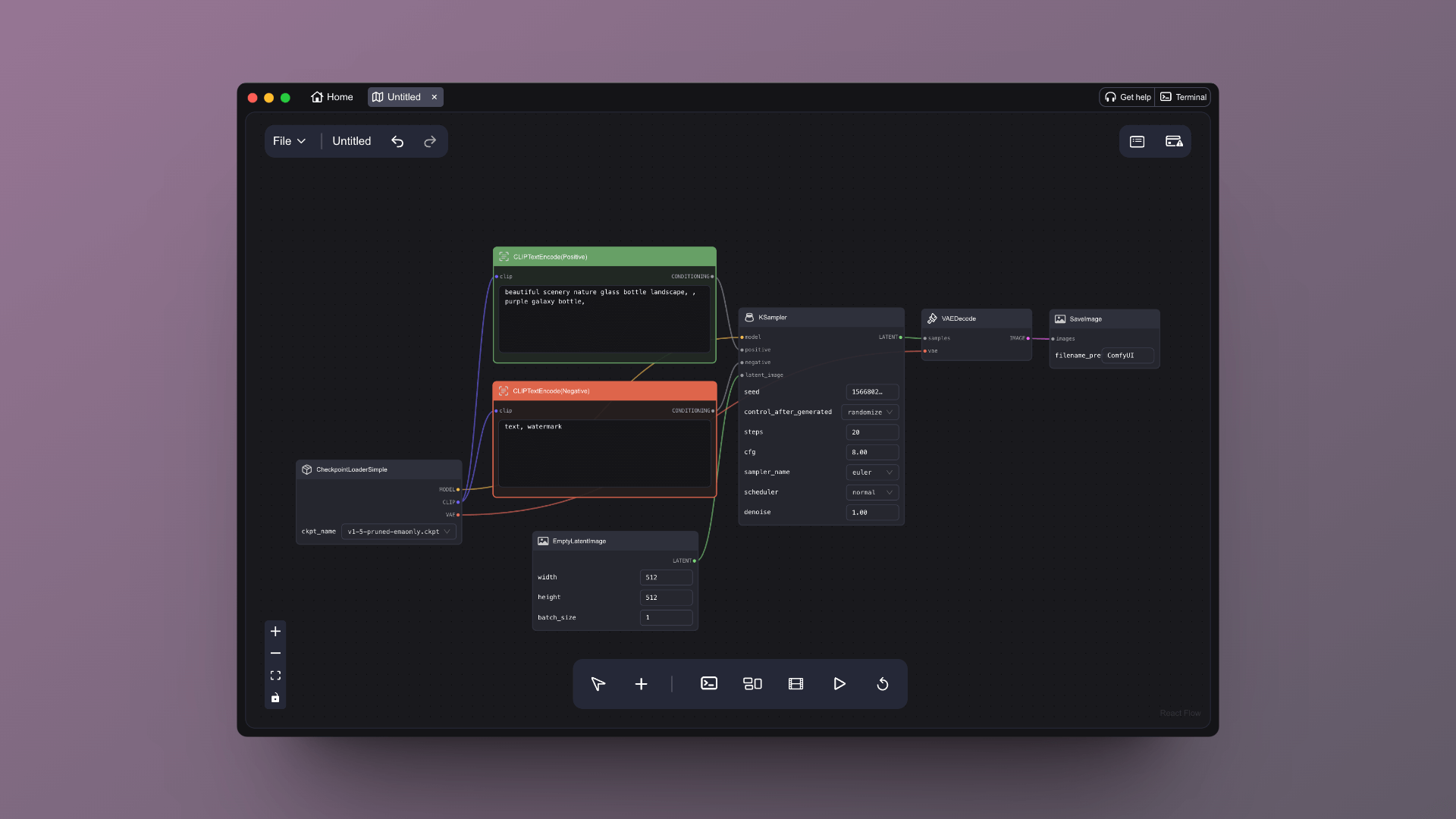
你可以点击下方面板的那个 Run 按钮(下方那个播放按钮)既可以运行 AI 文生图。最终你会在最右侧的 Save Image 看到生成的图片。
尝试完文生图后,你可能会很疑惑,这些方块和线都代表什么?
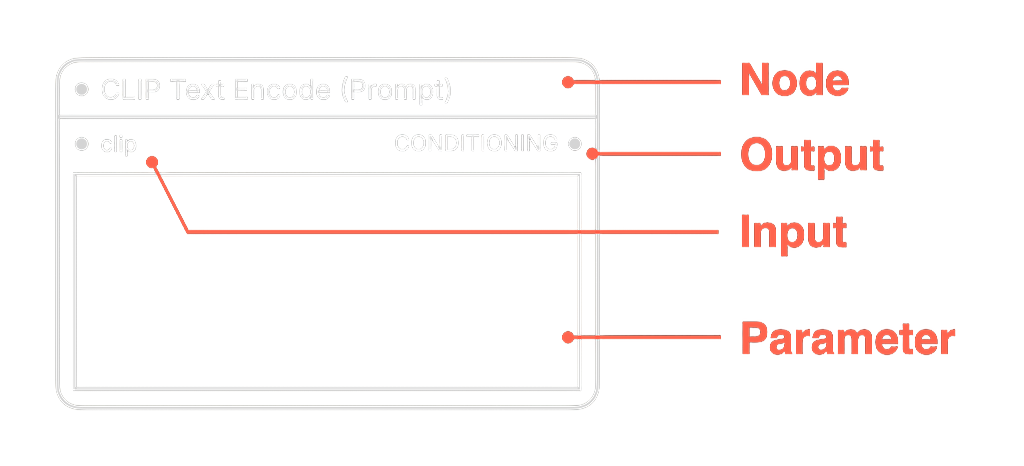
为了方便后续的介绍,我先简单介绍下里面的一个个方块。这个方块我在后续会称其为 Node(节点),其左侧端点是 Input(输入)端,右侧是 Output(输出)端,节点里还会有一些配置项,这些配置项我会称其为 Parameter(参数):
然后我们再看回这些节点,其实里面的节点我们在上一章中都有提到过。我稍微调整下里面的顺序,你应该就很熟悉了(图片可以点击放大 👇):
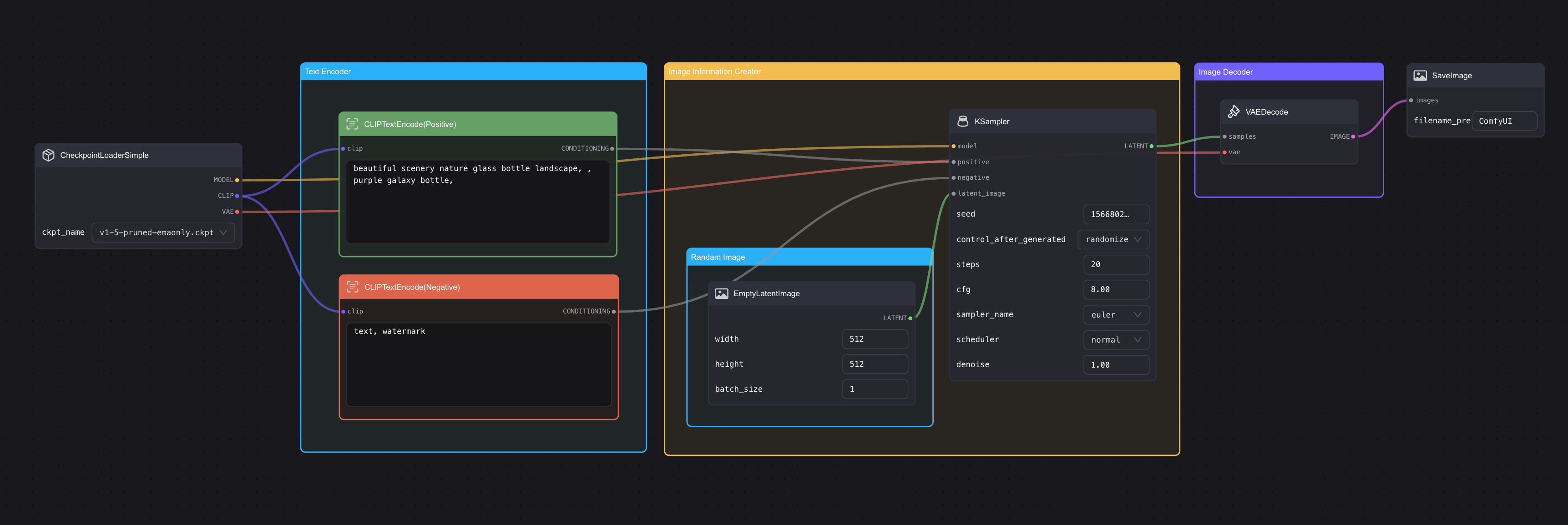
现在再看看,这些方块是不是变得似曾相识了?初始 Workflow 上的这些块块(后续我会用「节点」来称呼这些块块),其实就是前面一章中提到的 Stable Diffusion 包含的三大组件,只是这些组件在 ComfyUI 里名字不太一样而已:
| 节点名称 | 在 SD 模型里对应的名称 | 解释 |
|---|---|---|
| CLIP Text Encode | Text Encoder | 还记得上一章我们提到过 Stable Diffusion 的 Text Encoder 用的是 CLIP 里的 Text Encoder 吗?其实这个组件和上一章提到的 Text Encoder 是一个东西。只是说这里有两个,但如果你沿着输出端的连线往下看,你会看到两个节点分别连接 positive 和 negative 端,这就意味着它们一个是正向 prompt 一个代表负向 prompt。 |
| KSmapler | Image Information Creator | 这个对应的就是我们的最核心的模型生成图片的部分,在 ComfyUI 里名字差异比较大,且配置项很多,在后续章节我会详细讲解。 |
| Empty Latent Image | Image Information Creator | 上一章我们也提到,整个生图过程是在 Latent Space 里进行,所以在 ComfyUI 里的这个节点叫 Empty Latent Image。 |
| VAE Decoder | Image Decoder | 整个生成过程都在 Latent Space 进行,上一章中我有提到过,该过程全称为 Variational Auto Encoder(变分自编码器)简称 VAE,所以这个在 ComfyUI 里就被称为 VAE Decoder 了。 |
然后两端各有两个上一章没有提到的东西:
- Save Image:顾名思义,就是保存输出后的图片。
- Load Checkpoint:这个你可以理解为图片模型加载器。比如 Stable Diffusion 就有 1.5、XL、XL-Turbo 等版本,要切换或载入不同的模型,就需要用到这个节点。
节点介绍
看完整个 Workflow 后,我们再来详细介绍下每个节点的配置。我们从左往右开始介绍各个节点。
Load Checkpoint
第一个是 Load Checkpoint,从节点的右边输出端点可以看出,Checkpoint 包含了三个部分:MODEL、CLIP 还有 VAE,这三部分其实就是之前介绍的 Stable Diffusion 的模型三大步骤。可以说这个节点是所有 Workflow 的起点。
点击节点里的选项按钮可以切换模型,这里只能切换你已经下载好的模型,关于如何下载模型可以看对应的章节。
说到模型,我想再强调下,一般你会看到两种后缀的模型:
-
safetensors:这种模型一般用的是 numpy 格式保存,这就意味着它只保存了张量数据,没有任何代码,加载这类文件会更安全和更快。
-
ckpt:这种文件是序列化过的,这意味着它们可能会包含一些恶意代码,加载这类模型就可能会带来安全风险。
我建议各位优先下载和使用 safetensors 后缀的模型文件。
另外,你还可能看到有些模型在名字里会标注为 fp16,这是什么意思呢?
这个是 half-precision floating point format,即半精度浮点格式。这种格式相比标准的 32 位浮点数,占用的存储空间更小,且运算速度更快。但它生成图片的精度,以及多样性相较完整版会稍微差一些。所以如果你想要更快的得出结果,可以考虑 fp16 版本的模型。
CLIP Text Encode(Prompt)
接着是 CLIP Text Enocode 节点,CLIP 全称是 Contrastive Language-Image Pre-training,即对比文本图像预训练。这个节点主要是输入 Prompt。一般会有两个这样的节点,一个是正向的 Prompt,列你希望在图片中看到的内容;另一个是负向的 Prompt,列你不希望在图片中出现的内容。
一般说来,写 Stable Diffusion 的 prompt 有几个原则:
- Prompt 并不是越长越好,尽量保持在 75 个 token(或约 60 个字)以内。
- 使用逗号分隔。Stable Diffusion 并不懂语法,所以你需要将画面中的关键词罗列出来,并用逗号分隔。
- 越重要的词放在靠前的位置。比如你想要生成一张美丽的风景图,那么你可以将 beautiful scenery nature 放在最前面。
另外,还有个小技巧,你可以输入 (keyword:weight) 方式来控制关键词的权重,比如 (hight building: 1.2 ) 就意味着 hight building 的权重变高,如果填写的权重数小于 1,则意味着这个词的权重会变低,生成的图与这个词更不相关。
Empty Latent Image
然后是空的潜空间图像节点。如果你需要调整最终生成的图片的大小,就需要调整 width(宽)、height(高)这两个值。而 batch_size 则是设置每次运行时生成的图片数量,比如你将这个设置成了 4,就意味着每次会生成 4 张图。
如果你使用的是 SD v1.5 模型的话,最优的大小是 512x512,部分基于 SD v1.5 微调的版本也支持 768x768。所以其常见宽高比有:
- 1:1(正方形):512x512、768x768
- 3:2(横向):768x512
- 2:3(纵向):512x768
- 4:3(横向):768x576
- 3:4(纵向):576x768
- 16:9(宽屏):912x512
- 9:16 (竖屏): 512x912
如果你使用的是 SDXL 模型的话,最优的大小是 1024x1024,其常见宽高比有:
- 1:1(正方形):1024x1024、768x768
- 3:2(横向):1152x768
- 2:3(纵向):768x1152
- 4:3(横向):1152x864
- 3:4(纵向):864x1152
- 16:9(宽屏):1360x768
- 9:16(竖屏):768x1360
最后,需要注意宽度和高度必须能被 8 整除。
你可能会好奇,为何有些模型图片大小设置成 512X512,生成的效果会非常诡异(比如两个人头),而有一些模型,比如 SDXL 默认大小就是 1024x1024 呢?主要的原因是这些模型在训练的时候,训练的图片大小不同,像 SDXL 训练用的就是更大的图片。如果拿雕刻做类比的话,这些模型就像是雕刻家,他们需要通过训练学习的方式学会雕刻大理石。而有一些雕刻家在学的时候,用的就是 1024x1024 的大理石,没有学过 2048x2048,所以雕刻大的大理石效果反而不好。
Save Image
完成图片生成后,对着图片点击右键,会看到「Save Image」的选项,点击此按钮就可以下载生成好的图片。节点里的输入框,则是设置图片名称的前缀。比如默认是 ComfyUI,那就意味着你保存的图片的文件名是 ComfyUI 开头,后面跟着一串数字。
KSampler
最后是 KSampler,Sampler 中文名称是采样器,如果你想详细了解采样器,可以阅读相关进阶教程,而基础教程只会告诉你如何使用。KSampler 包含以下参数:
-
seed:这个是随机种子,它主要用于控制潜空间的初始噪声。如果你想重复生成一模一样的图片。就需要用到这个随机种子。需要注意种子和 Prompt 都要相同,才能生成一模一样的图。举个例子,你可以使用 Default Workflow 的默认 Prompt(beautiful scenery nature glass bottle landscape, purple galaxy bottle),生成一张图片。接着将这个随机种子 copy 下来比如 156680208700286,然后将 Prompt 里的 purple 改成 green,生成一张新的图片,再将之前复制的种子 156680208700286 覆盖黏贴到新种子上,然后将 Prompt 改回原来的 purple,重新生成图片。你会发现此时生成的图片与第一次生成的图片是一模一样的。
-
control_after_generate:每次生成完图片后,上面的 seed 数字都会变化,而这个配置项,则是设置这个变化规则:randomize(随机)、increment(递增 1)、decrement(递减 1)、fixed(固定)。
-
step:采样的步数。一般步数越大,效果越好,但也跟使用的模型和采样器有关。
-
cfg:全称 Classifier Free Guidance,我在 SD 基础一章中有介绍过,这个值设置一般设置为 6~8 之间会比较好。
-
sampler_name:采样器名称。你可以通过这个来设置采样器算法。如果你对它感兴趣,可以阅读相关的进阶教程。
-
scheduler:调度器主要是控制每个步骤中去噪的过程。你可以通过它选择不同的调度算法,有些算法是选择每一步减去相同数量的噪声,有些则是每一步都尽可能去掉多的噪声。
-
denoise:表示要增加多少初始噪声,1 表示全部。一般文生图你都可以默认将其设置成 1。
最佳实践
在各个配置项中,除了模型会影响出图的结果外,其次就是 KSampler 的几个配置项,进阶教程会分享各个采样器的特点,本章节,就只分享下最佳实践:
| 需求 | checkpoint | sampler_name | scheduler | step | cfg |
|---|---|---|---|---|---|
| 非常在意速度 | SDXL Turbo fp16 | dpmpp_2m(有些软件会叫它 dpm++2M) | normal 或者使用 Turbo 专用 scheduler | 1-2 | 6-8 |
| 非常在意图像质量,同时在意生成图片内容多样性 | SDXL refiner | dpmpp_2m(有些软件会叫它 dpm++2M) | karras | 20-30 | 6-8 |
| UniPC(相较于 dpmpp_2m 会更快一些) | karras | 20-30 | 1-2 | ||
| 在意图像质量,不太在意多样性,但想提高生成速度 | SDXL refiner fp16 | dpmpp_sde | karras | 10-15 | 6-8 |
| ddim | normal | 10-15 | 6-8 |
补充说明下,KSampler 的配置跟模型(checkpoint)比较强相关,比如 SDXL-Turbo 因为对图片生成过程进行了压缩,其最佳 cfg 反而不能太大,实验下来,可能 1 或 4 最好。另外,你在下载别人的模型的时候,作者一般会在模型介绍中写明最佳的参数配置。你可以按照这个配置去设置参数。
我目前比较常用的是 SDXL Turbo,另外使用什么模型还取决于你的做图需求,各位需要根据场景自行斟酌,并且多尝试。
连线
最后,了解完基本的配置后,我们再来看看连线和基本操作。
千万不要被这些看似繁琐的连线所困扰,觉得这很难懂。甚至有种拆炸弹的感觉,不知道应该剪红线,还是剪黄线 😂
其实这些节点就像是一个个乐高一样,能自由组合的同时,还有一定的规则,我们拿图中连线点最多的 KSampler 为例:
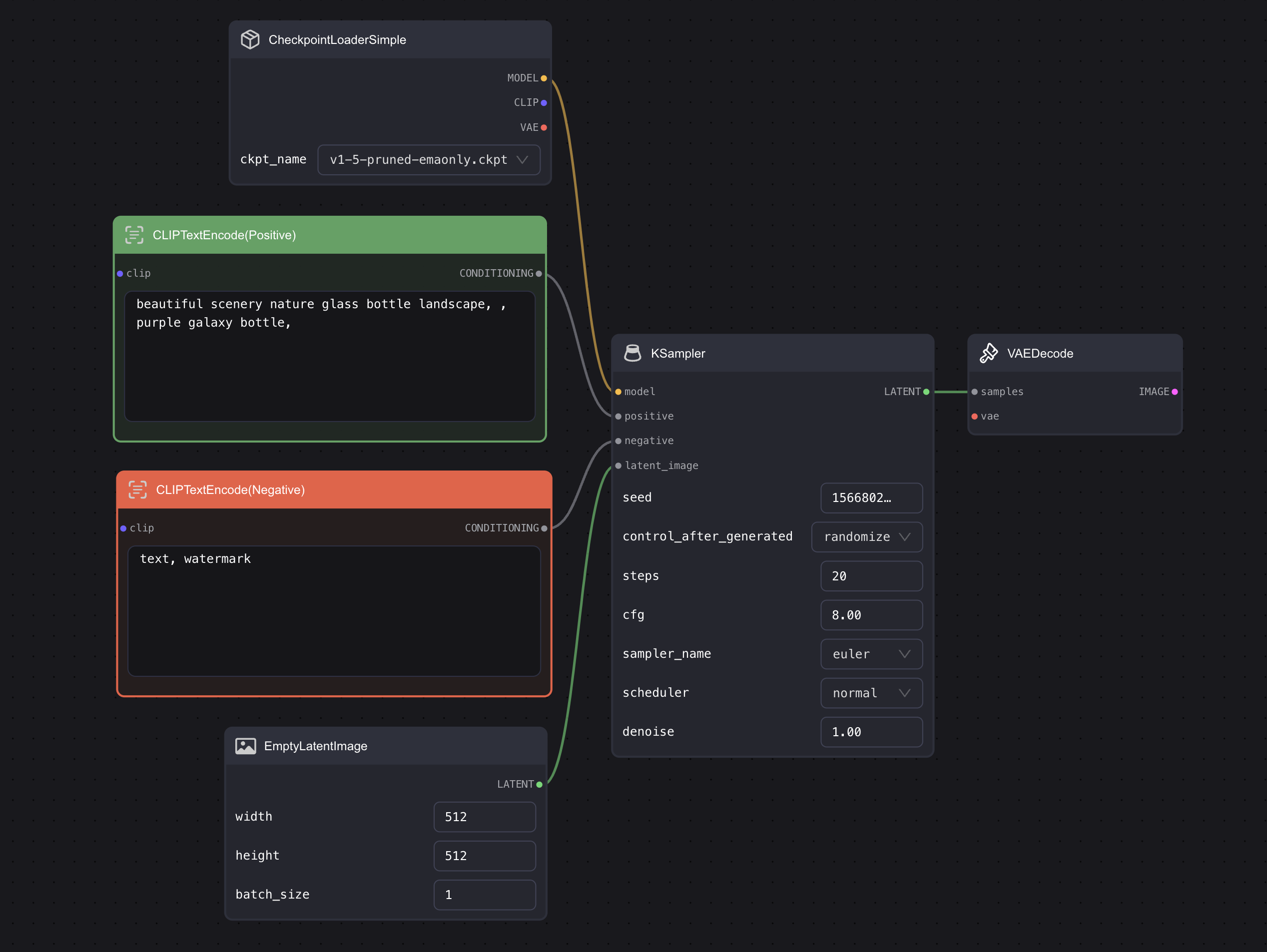
如果你细看这些连线,会发现这些线和连接点都有对应的颜色,并且还有一些文字说明。简单总结一下连线的规则,懂了这些规则后,连起来基本上不会有问题:
-
同类相连:只有同类才能相互连接起来,比如 KSampler 左侧的 model 端点,就只能跟另一个 MODEL 输出点相连。或者跟具象点说,只有同颜色的端点能相连,如果你将 CLIP Text Encode 右边橙色的点,连到 KSampler 的紫色点 model 上是不可能的。因为他们类型不一样。橙色点只能跟橙色点连。另外,还有一个技巧,当你点击端点并拉出一条线的时候,只有那些能连接的线会高亮出来,不能连的会变暗。
-
左进右出:比如 KSampler 左边的 model、positive、negative、latent_image 都是是输入端,输出端是右边的 LATENT。你可以将其理解为一个函数,左边输入数字,右边是输出。那也就意味着你不能将一个节点右边的输出端,连到另一节点右边的输出端。
-
一进多出:一个输入端只能和另一个节点的输出端相连,没法和多个输出端相连。比如上图中的 KSampler 的 positive 端点,只能和一个 CLIP Text Encode 相连,没法同时连多个。但一个输出端,能和多个输入端相连。还是上面那个例子,一个 CLIP Text Encode 可以和多个 KSampler 相连,比如可以和 KSampler A 的 positive 端连,也可以和 KSampler B 的 negative 点连,最后出两张图。
了解这些规则后,你基本上就不会不知所措了。后面我会介绍更多的案例,你会越来越熟悉这些规则。
练习
简单介绍完基本的连线操作后,我们来完成一个小练习,让你能将这两章的内容融会贯通。
首先,点击右边的 Clear 按钮,将 Default Workflow 都清除。
然后从零完成以下目标:将 Empty Latent Image 转为人能看的图片。
如果你找不到你想要的节点时,点击右键 → Add Node → loader 里看看。应该能找到。
Q&A
运行基础 workflow 时,KSampler 报错该怎么办?
完整报错信息:Error occurred when executing KSampler: module 'torch' has no attribute 'mps' This issue is from Discord user 123321123.
Answer from Jimmy: 看这个报错应该是没有安装最新 pytorch 导致的。更新下电脑的 pytorch 版本即可。